
The humanity had started searching long before the beginning of modern computer century. Thanks to the common sense people invented indices. Libraries, dictionaries, maps made the life easier for the next generations of knowledge hunters. And now you as a software developer face the necessity to implement your own search functionality. Usually you can meet search-related requirements at the end of the customer's list. But, in my opinion, they influence significantly on the final architecture of the system. Furthermore, the search index is the foundation of searching, its design errors can lead to the wrong choice of storage or database that can break your system in general.
** Databases**
All databases relates to one of the following category by their logical structure: Key Value (NOSQL) Row Oriented (SQL) Column Oriented(SQL or NOSQL) Document Oriented (NOSQL) Graph (NOSQL)
In standard cases inside the same type you can easily replace one database to another taking into accounts their general kinds of SQL and NOSQL (The difference between Cassandra and Vertica is significant, the same as the difference between MySQL and Redis in spite of both are the Column Oriented stores. Further, I will just say Relational about Row Oriented and SQL Column oriented, as they both implement the same specifications). However, this kind of replacement doesn't usually have sense.
When you need to replace one database to another across the different types at the best case you will just reimplement all interactions with the database in your search component. At the worst it will result changes of other components of your system. Thus, it is crucial to get the detailed search requirements. There is a risk to make any significant changes during the implementation.
Let us suppose you've got all the requirements and you can start structuring the data. Any structures (or indices) you build make sense if only it satisfies your search needs.
We should rely on common sense. We are always looking for something (home keys, parking space, mobile phone, etc). I consider it is useful activity that makes us think, although all our routine lookups have 2 common sides. Firstly, we have quite good knowledge about the quantity and structure of the data across which we are searching, so our expectations about the final result are based on that knowledge. Secondly, we know exactly what object we want to find. In other words, we try to reduce the number of the final results using different criteria. We can call it the filter.
** Filters**
Imagine the situation when you can't find your mobile phone. If there is somebody who can dial your number you'll easily resolve the problem and probably find your phone under the cushion on the sofa. But if there is no one who can help you, you will use another criterion (something of white color with the button beneath) implying that the room where you are searching is not the production warehouse.
** Unique filter**
If you know a unique property of the object among available data you will easily find it. Therefore, you don't need to know other properties of the object as you can find it using only one unique feature.
Applying to the development it means if you meet the unique criterion in search requirements it doesn't make sense to join this criterion to others. If you meet the unique criterion in search requirements it doesn't make sense to join this criterion with others. As the result you can identify the primary key, or you can use different indices or even different databases in searching for unique criterion or other criteria.
** Non-unique filter**
Let's make the situation a little bit more difficult. For example, you need to implement filtering using by the non-unique criterion or combination of filters. Sometimes you have to reject Key Value databases. They usually don't support such an operation or it is resource-consuming . You should understand which filters can be combined and which can't as well as who applies these filters. The example can be online shop selling the goods of any categories (food, clothes, electronics, etc). Nobody will look for the 100% cotton kettle with the hdmi output.
** Relationships**
Now let review the more complicated situation. Your objects have the relationships and you should take them into account while filtering. If you are sure that you are able to implement all filter requirements using one database you are on the crossroad now. On the one hand, you have Relational and NOSQL Column Oriented databases, on the other hand, there are Key Value and Document Oriented, and Graph is somewhere between them.
It is obvious that you can index any relationships in Relational databases, however, if you have recursive relationships between the objects the problems come with requirements relating to the graph bypassing.
Graph is more applicable in this case. As for NOSQL Column Oriented it is closer to Relational databases than Graph. Key Value and Document Oriented aren't designed to support the relationships between the schemas, however, you can implement non-recursive relationships by using the data denormalization within one schema, some databases of these types support relations between the schemas, but pay attention to the limits section of the documentation, perhaps you can't use this functionality.
Realistic example
Let's describe the real situatuion. We have 2 types of objects: Project and Collection. A user creates projects and combine them into a collection. You have to search projects by collections and filter them by the creation date. And you have some millions of projects.
Suppose that we have found out additional requirements after discussions with the customer.
- There aren't any restrictions on inclosing the project into the collection.
- You can put the collection into another collection. This action is unlimited as well. And in the future you will need to display the total number of all collection entries of all levels. This example is similar to the real system case and, in my opinion, it contains the error in the design. The domain model is too abstract for the data domain, thus, the final solution has the complicated logic and it is quite difficult to test it.
Indeed, the final users are mostly artists, designers, engineers, architects. The real Project is a result of the human mind. And collections serve to group projects by some clean criteria such as the project's author, the content, etc. So does it really make sense to include any projects into any collections? If I were an interior designer I wouldn't put my project into the collection of aircrafts. And I wouldn't include my collection into other designer's collection. Instead I would use a collection to organize my projects and I'd prefer to have some kind of tags to define the domain of my projects.
Thus, the data domain plays an important role in the search functionality design. You should investigate the domain terms and probably use DDD practices if the area is absolutely unknown for you. Because it is hard to support redundant relations in the data. It usually results in the difficult search logic or problems in the architecture, in general.
For example, if the requirements or the data domain imply contextual relations in the search criteria (such as the authorization role or the access policy), it will be better to know about this as early as possible. Otherwise, it can be difficult to implement them after you have chosen the Key Value or the Document Oriented database type. Non-contextual relations are possible to support in those database types by the denormalization, the business logic level or you are satisfied with the database restrictions.
Turning to our example, suppose that we have changed the domain model and we have split 2 terms – the collection and the catalogue, so we have:
- The collection is a folder which the user creates to organize the projects. The collections aren't of great value for analytics, the users can put anything they want. The collections and projects graph should represent a tree.
- The catalogue relates to the project domain. The user can put the project into several existent catalogues, but its number is limited.
- The catalogues are independent and don't have any relations between each other. The catalogue is a kind of a tag.
- The catalogue's name is unique and there isn't a great number of catalogues in comparison with projects. There are some restrictions on the catalogue creation as well. Thus, we need the projects filtered by the catalogue and the creation date. In the future we will implement the catalogue size statistics and probably some limited hierarchy of the catalogues. We need to implement the projects filter by the collection as well. We assume that collections don't contain many projects so we don't need to implement some additional filters.
Regarding the database, I would exclude the Key-Value type, because it isn't convenient to perform queries by non-unique criteria.
- Relational
The relation between collections and projects is one-to-many, so we can just include the collection key into the projects table. And the relation between collections and catalogues is many-to-many, so we can have the separate table to maintain it.
collection
| id | … | |---|---| | primary key | … |
project
| id | creation_time | collection_id | … | |---|---|---|---| | primary key | indexed timestamp | foreign key to collection.id | … |
catalogue
| id | name | … | |---|---|---| | primary key | unique key | … |
catalogue_project
| catalogue_id | project_id | |---|---| | foreign key to catalogue.id | foreign key to project.id |
- Key-Document
We can index the catalogue keys (or names) inside the project document, as its amount is significantly less than projects'.
{
id : "key",
creation_time : "timestamp",
collection_id : "indexed value",
catalogues : ["indexed array"]
}
- Graph
We map the document from the previous schema to the graph.
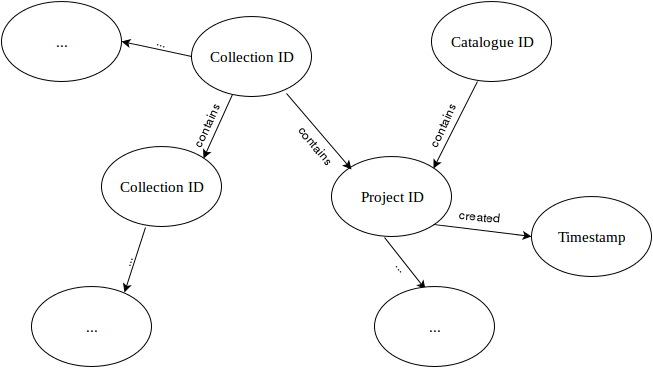
Perhaps, it is very tricky for this standard issue, however, Neo4j, for example, easily supports such a filter . If you are going to have very different 'documents' and you need the extremely flexible schema and complex filters, you don't want to have a huge combination of 'AND' and 'OR' operators in queries, the graph structure can be the better variant for you.
- NOSQL Column Oriented
It depends on the database logic. If you look up the Cassandra, for example, you need to map your query to the single table. In the case of the limited number of catalogues for the project you can use the table like this:
project
| id | creation_time | collection_id | catalogue_names | … | |---|---|---|---|---| | primary key | | | set | … |
Or if you don't need to retrieve the catalogue itself with the project you can use the following denormalized table:
project
| id | catalogue_name | creation_time | collection_id | … | |---|---|---|---|---| | primary key(id | , catalogue_name) | | | … |
In conclusion I would like to make the following points:
-
The requirement of the unique filter isn't difficult to implement.
-
There are 2 groups of the non-unique filters: relational and non-relational.
- Relational filters lead to the limitations of your database, you should know about them as early as possible.
- Non-relational filters can lead to the limitations of your database, however, they aren't significant.
-
The combined filters must be implemented relying on common sense. With regard to the filter all data is equal in terms of the search results order. If your search functionality requirements contain the non-unique filter with the pagination you will have to create the artificial order of results. In general, sorting is provided by the database, however its usage may have the negative performance effect.