
Today I'm going to tell you about Git version control (branching) model that we use widely in ISS Art to effectively manage code base of our projects. The experienced software development teams might know this model as major ideas were found long time ago and posted in the articles:
- Version Control for Multiple Agile Teams by Henrik Kniberg
- A successful Git branching model by Vincent Driessen
Here, I'm going to consolidate these ideas in the way that could be easily understood by software project managers, product owners and decision-makers to explain them the technical challenges that can arise due to certain harmful business decisions, and how they can impact development costs and schedule. Examples of harmful business decisions:
- Task reprioritization after development start
- Request to include one more feature in release during release testing
- Too many hotfix requests
Issues that version control can resolve
If your team is not experienced enough in collaborative software development process, you probably face the next troubles from time to time:
- Code conflicts block the development until resolved
- Testing blocks the development until finished
- It is hard to switch between the tasks
- Code is not ready to be released the most of time
- It is hard to fix the defects (i.e. client's bug reports)
- It is hard to fix the release bugs (i.e. tester's bug reports)
Let me show you an example. Meet this awesome team, starring:
|  |
|  |
|  |
|  |
|---|---|---|---|
| Donkey Eeyore | Junior | Lion | Server |
| Lead developer | Developer | Tester | Buzzing in the corner |
|
|---|---|---|---|
| Donkey Eeyore | Junior | Lion | Server |
| Lead developer | Developer | Tester | Buzzing in the corner |
They are working on some important project. They have created a Git repository to share and manage their code. They don't worry about branching. They use only master branch, because the team is small, and this approach fits their needs very well (which is not true, but they think that it is). They have already deployed their first release on production, and here come the troubles…
Code conflicts strike hard
Junior has managed to code something:
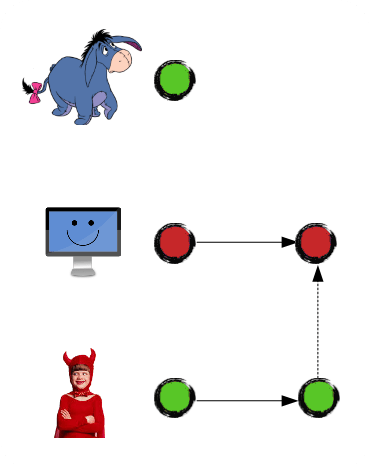
And went on vacation:
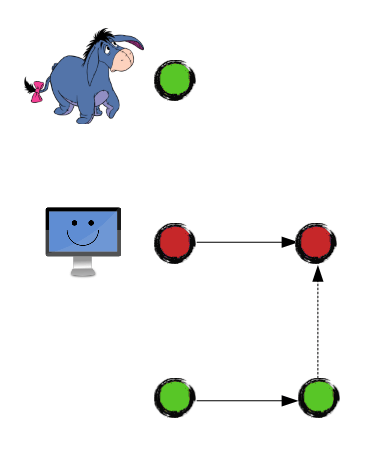
Meanwhile Eeyore fixed a super-critical bug:
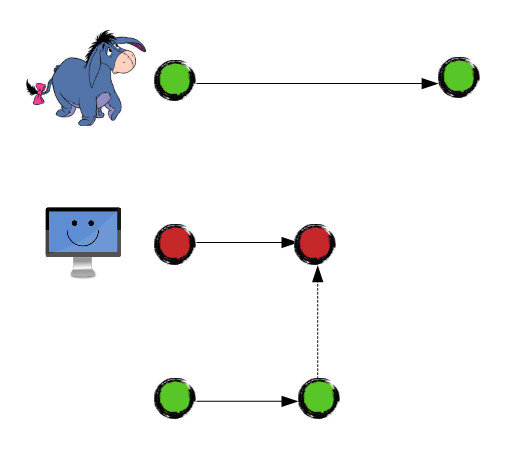
But he was unable to commit it, because there is a code conflict with Junior's code:
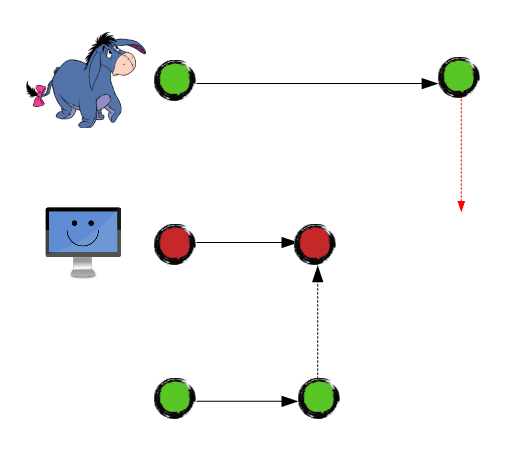
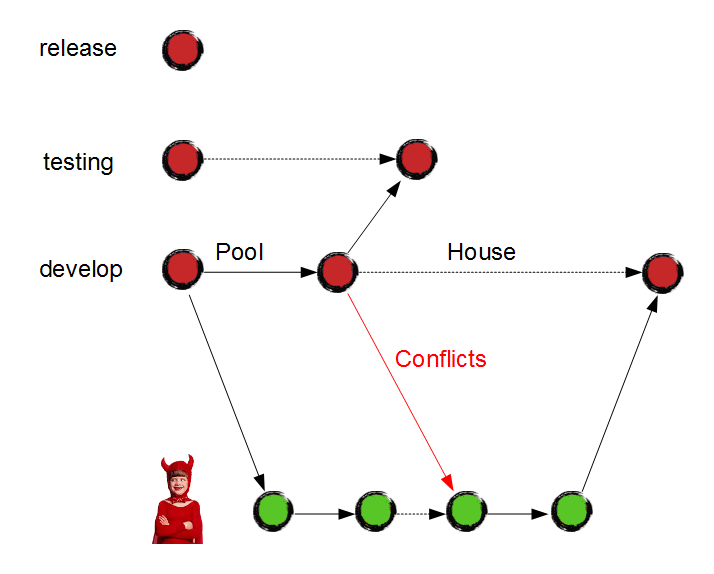
So, Junior's low-priority code gets in the way of the super-critical bug fix. Eeyore can't resolve the conflict efficiently without Junior's assistance, because Junior's code is awful.
Releases are hard to get deployed
Eeyore worked on the development of the pool:
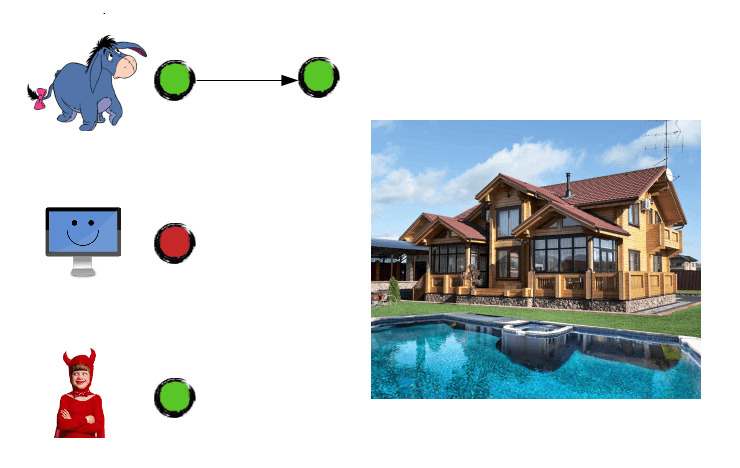
Meanwhile, Junior was creating a garden house. Slowly, step by step, because that's what real guys do:
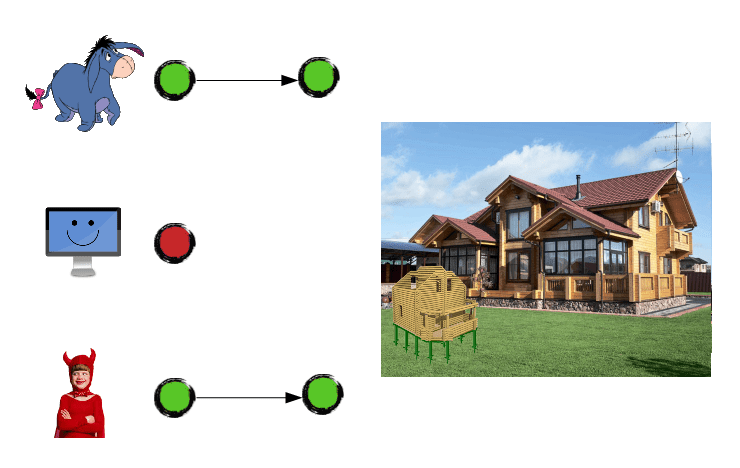
One of them was forced to deal with the code conflict. Guess who:
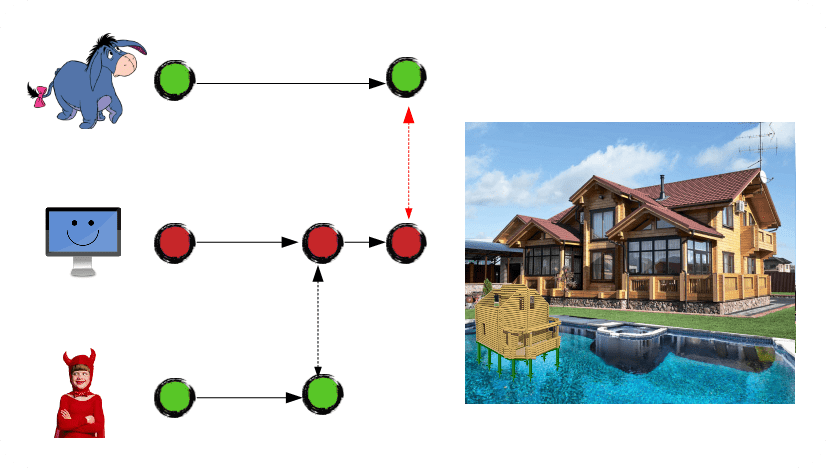
It is no more a garden house – rather, it is a "pool house". It is not finished yet. And for some awkward reason, the client asks the team to deliver whatever is done so far.

Is he satisfied? I don't think so…

The ridiculous part of this story is the fact that these issues can be easily resolved with a proper code version control. Let me tell you how!
Version control pattern
Apparently, there are many successful branching models which can help you to avoid all the listed problems. You can even create an own one for your team. But all these branching models are based on a common general idea – version control pattern.
Branch is determined by policy and owner.
Branch policy is a list of constraints imposed on any code present in this branch. We usually apply the next policies to our branches:
- Code convention rules are respected.
- Code compilation succeeds.
- Code is reviewed by a peer/two peers/lead developer.
- Unit tests succeed.
- Integration tests succeed.
- All features are complete. No partial work allowed.
- All but one specific feature are complete.
- Application is tested manually.
- No new features allowed since the branch is created.
Branch owner is a person who is responsible for policy observance. The owner determines branch policy and makes sure that every team member follows it.
If every branch has a policy and an owner, we can claim the next conventions:
- A new branch gets created when someone needs to commit some code restricting policies of all existing branches. So, he creates a branch with reduced policy to commit it.
- A branch gets merged to another branch if the merged code meets policies of both branches.
Usually it is possible to compare branch policies. Branch A has tougher policy than branch B if the code in branch A meets the policy of branch B as well at any point of time, but not vice versa. In this case, we say that branch B has softer policy, and branch A is higher than branch B (on history diagrams, a branch with tougher policy is always drawn higher than a branch with softer policy).
With that said, there are two merging scenarios:
- Higher branch can be merged down to a lower one at any point of time. Ideally, any code modification in a higher branch should be applied to all the lower branches as soon as possible, because it will let you resolve code conflicts step by step, in small chunks. In this scenario, we say that the lower branch catches up the higher one.
- Lower branch can be merged up to a higher one as soon as the code starts meeting the higher branch policy. The earlier you do that, the faster this code gets shared with all the other branches, therefore developers will suffer fewer code conflicts. In this scenario, we say that the lower branch gets published to the higher one.
Let me show you some consequences:
- ince a developer creates a new branch to reduce the policies, branches are always created from top to bottom. So, a new branch is always lower than its base branch.
- Once a developer creates a new branch, his goal is to publish it as soon as possible.
- Before publishing, it is always smart to catch up the base branch. This way, all code conflicts get resolved in a lower branch before publishing, and the branch owner can validate the code against base branch policies once again.
- It also means that publishing is always copying – ode base gets completely copied from a lower branch to the higher one. After publishing, the code base in both branches is completely equal. So, you can delete the lower branch after publishing to keep your repository clean (at ISS Art, it is obligatory).
ISS Art branching model
Keeping version control pattern in mind, we use the next kinds of branches in our projects (from the toughest policy to the softest one):
- "release" (for production and hotfixes)
- "testing" (for release testing)
- "develop" (for the complete features)
- Feature branches (for development)
Feature branches

The softest kind of a branch. Do whatever you want here as long as the code can be compiled and executed.
Every feature branch is created to develop a separate application feature. By feature I mean a minimal chunk of code which brings some business value. Only one feature can be developed in a feature branch. So, you cannot create a branch to develop feature A, and suddenly switch to feature B without creating a new branch. It is a part of branch policy.
Sometimes features depend on each other, and you badly need to have the code base of another feature branch to carry on. In this case, you can use that branch as a base branch for yours, and claim the policy that only these two features are allowed to be incomplete. In future, once the base feature is done, its branch gets merged to "develop", and "develop" naturally becomes a base branch for the dependent one, and the development goes on as usual. If, for some reason, the dependent feature gets done faster than the base one, you can merge this code to base branch and delete the dependent branch. This way, two features become one bigger feature, and you should display it somehow in the task tracking system. We usually simply post a comment in the base feature to move the dependent one along the workflow once it is done, and it is enough. Alternatively, you can close the dependent feature as "Incomplete" and copy its description to the base one.
You should claim some naming convention for your feature branches. We use the ticket number joined with a short task name in lowercase, such as: <tt>23001-add-german-locale</tt>.
"develop" branch
Still full of bugs, but all features are done. The purpose of this branch is to let you quickly react to a release request and immediately start release testing at any point of time. There should be no partial features such as a button that cannot be pressed or a form that cannot be submitted. They confuse users and reduce conversion.
Since "develop" is higher than any feature branch, of course, code must be compilable and executable in "develop" branch as well.Unit tests must succeed, so a developer must run them before publishing his code to "develop".
Sometimes it makes sense to apply additional policies to "develop" branch, such as:
- All automatic tests succeed (incl. integration tests).
- All features are tested one by one.
These additional policies can slightly improve software quality, but require significant effort to maintain, and feature delivery time gets longer. So they are applicable only to big enterprise projects where quality is the key and budget is unlimited.
"testing" branch
Once the release date approaches or the customer decides to start release testing, we merge "develop" to "testing" to tighten its policies even more. In "testing" branch, no new features are allowed to be merged until the testing is finished. Of course, before publishing code to testing, you must make sure that all automatic tests succeed (incl. integration tests). Since "testing" is higher than "develop", all "develop" policies should also be respected.
If a tester reports a release bug, the fix branch gets created from the "testing" branch. Once the bug is fixed, the fix branch is published back to "testing". If the fix is simple, you can skip branch creation and fix the bug as long as "testing" branch policies are met.
"release" branch

Once the release is fully tested manually, and the tester confirms that the application is viable for productive usage, we merge "testing" branch to "release". In addition to "testing" branch policies "release" has the next restrictions:
- All features are tested manually.
- The application has no regressions (i.e. manual test plan succeeds).
- All quality standards are respected.
Example
Let's teach Junior and Eeyore our branching model and ask them to travel back in time and repeat the experiment. Before continuing, the guys create three main branches right away and declare their standard policies. Now, Junior must create a separate feature branch to build his garden house:
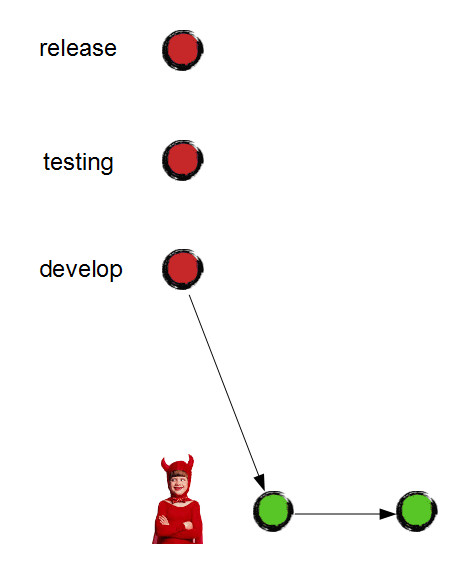
Meanwhile, Eeyore was working on the pool in a different feature branch:
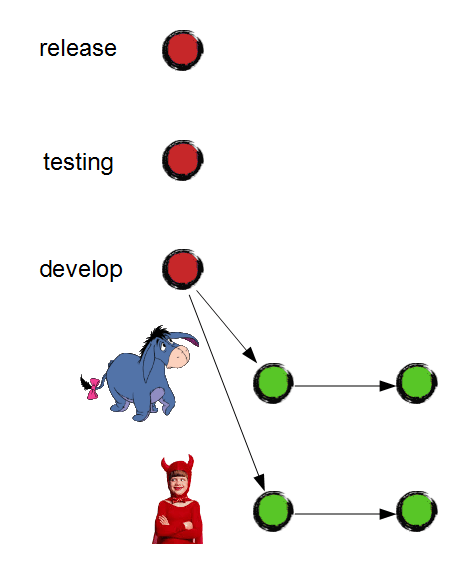
As soon as the pool is done and all unit tests succeed, Eeyore merges it to "develop" branch:
And delete the branch because it is no longer needed:
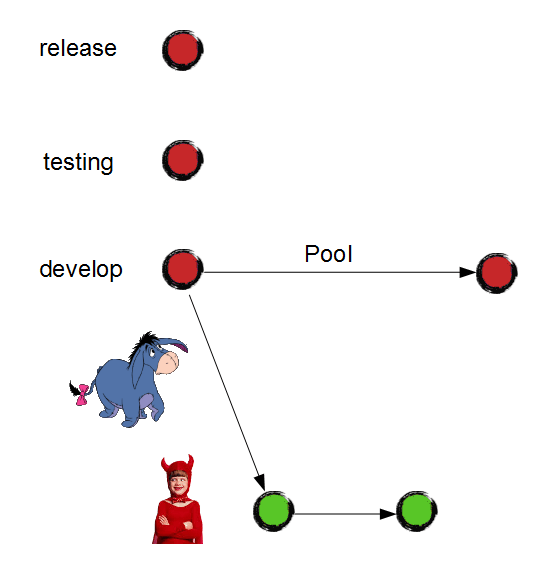
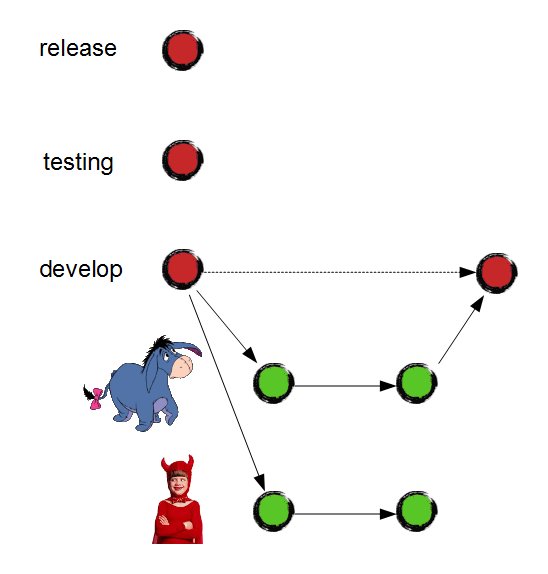
Junior can keep on building his garden house as long as he needs. At the same time, "develop" branch is ready for release. Will the client be satisfied? Of course!

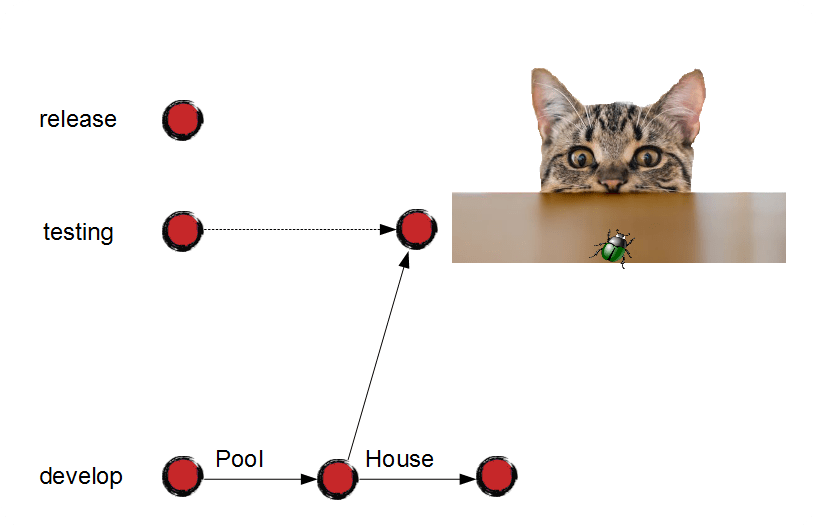
Before release delivery, we must test it carefully. To start testing, Eeyore and Junior make sure that integration tests succeed in "develop" branch. After that, they merge it to "testing" and deploy "testing" branch on the test server.
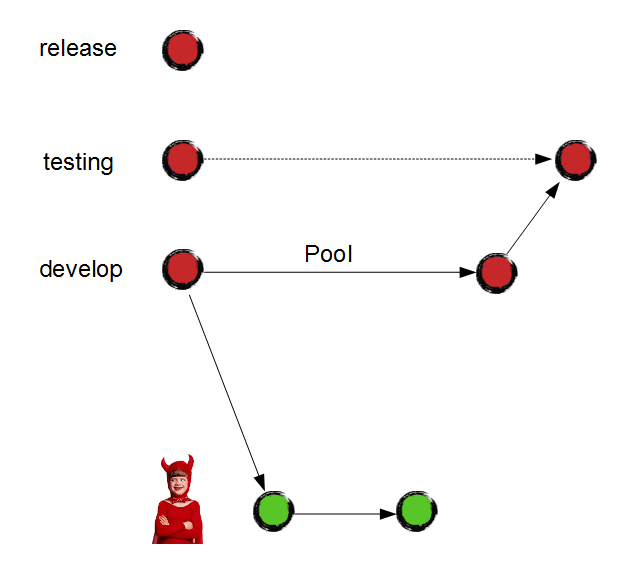
Please note that testing doesn't block further development. Junior catches up the pool feature very early and resolves the conflicts slowly and carefully. Once the garden house is ready, Junior is free to merge it to "develop" – it won't interrupt release testing because the branch policy doesn't allow Junior to merge his code to "testing".
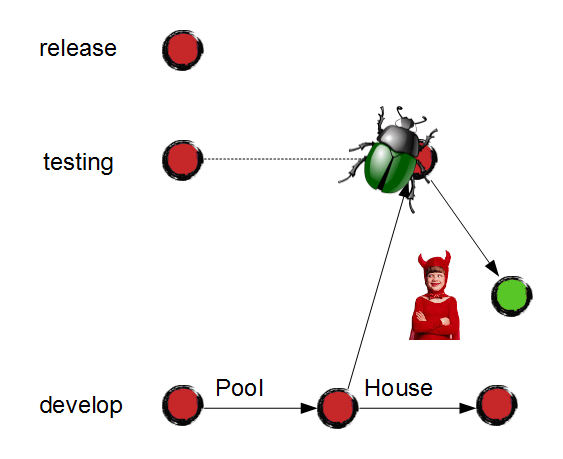
Let me show you what happens if the tester finds a bug in the release.
Junior creates a new branch from "testing":
Somewhere in a distant galaxy Eeyore starts the development of a new feature:
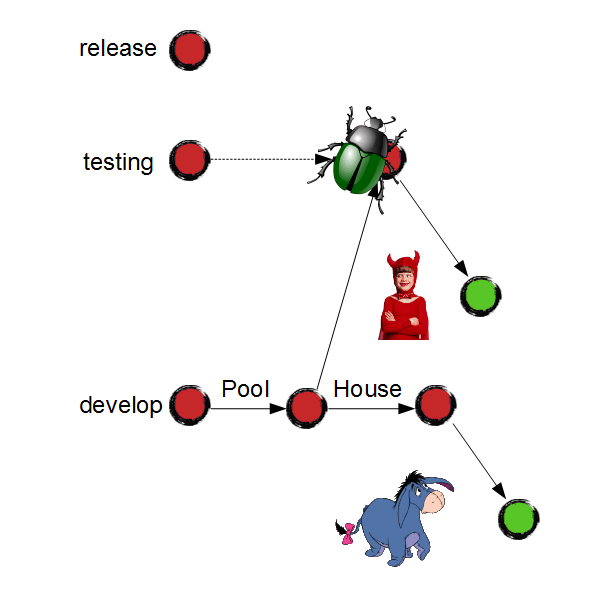
Junior gives incredible effort to fix the bug, while Eeyore is working on the feature:
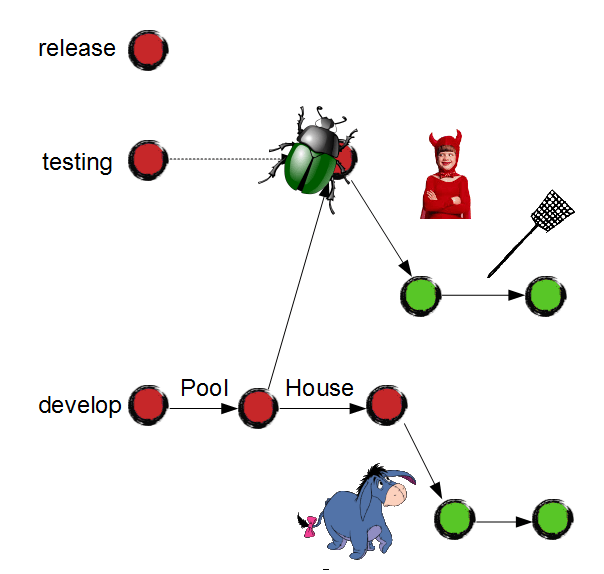
Once the bug is fixed and auto-tests succeed, Junior merges it to the "testing" branch and merges it down to "master" branch to share this achievement with the others:
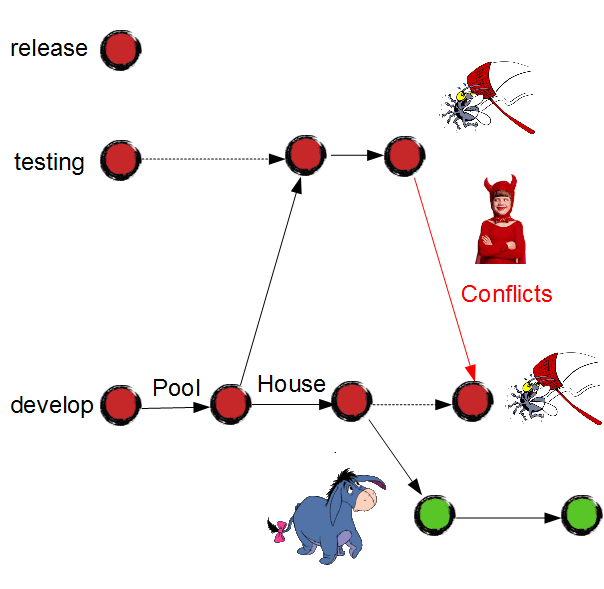
Next morning, Eeyore will catch it up in his feature branch:
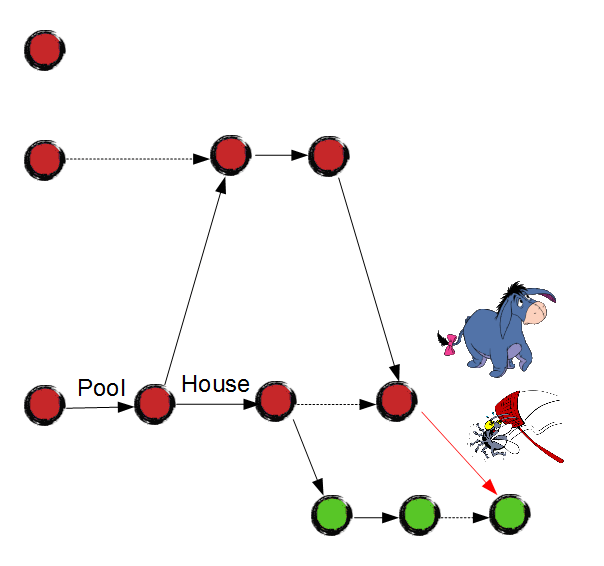
Meanwhile, the tester confirms that the application is ready for the productive usage. Eeyore and Junior merge "testing" branch to "release" and deploy it on the production server:
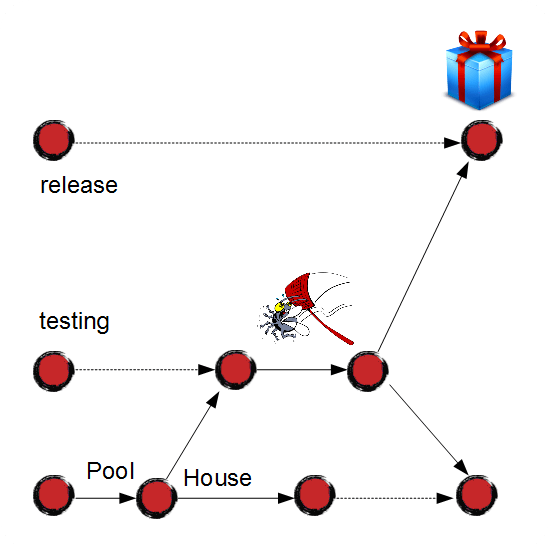
At some point, the client may call and report a critical bug on production that needs to be fixed as soon as possible.

In this case, we follow the same process and fix the bug in the "release" branch:
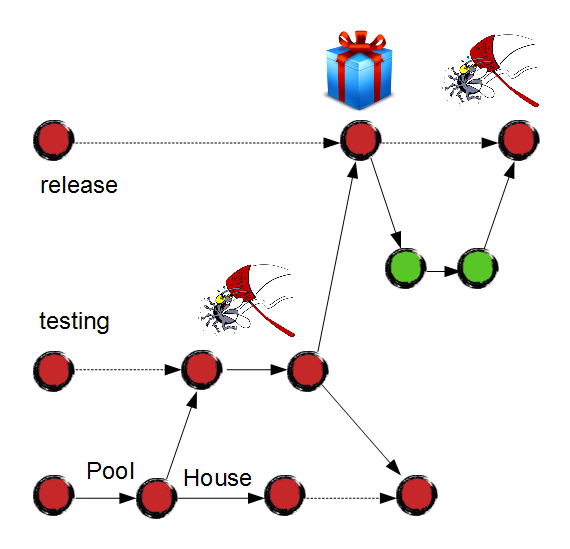
The fix gets merged to all the branches successively:
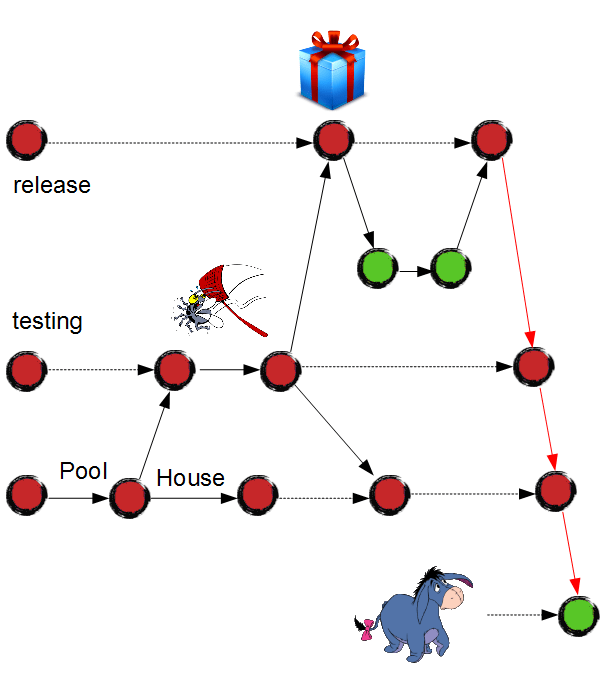
About cherry-pick

Git version control system has an awesome command available to the developers – cherry pick. It allows you to take a single commit and copy it to another branch. For example, provided a feature ready in "develop" branch, we can pull it to "testing" or "release" branch, commit by commit.
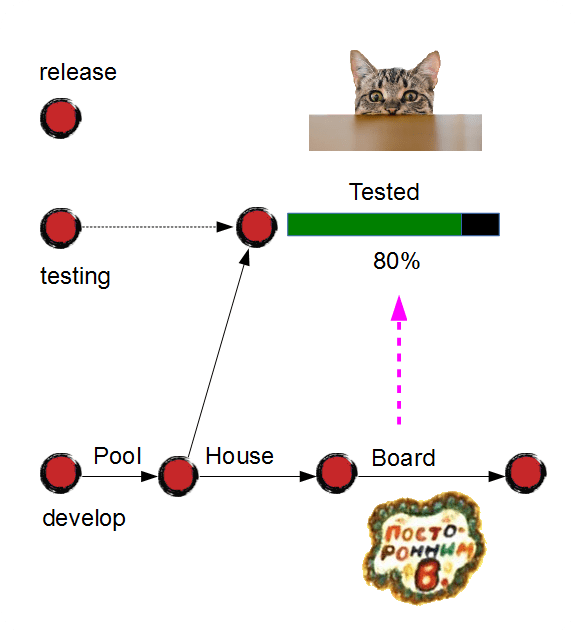
Please note that one does not simply merge simply merge "develop" branch to "testing", because in this case all the other features will get merged as well for no reason, and it will force the tester to start testing from scratch, so all current testing effort will be lost.
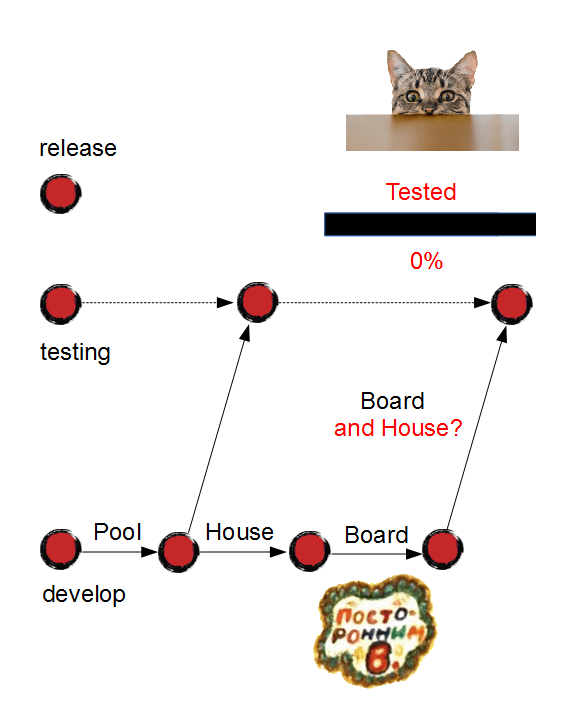
So, we must cherry pick a single feature to the "testing" branch.

And now let me explain you the dark part of this process. Please note that every single cherry pick may (and probably will) result in code conflicts. Because "Board" implementation can be completely different, whether we should have "House" implemented or not.
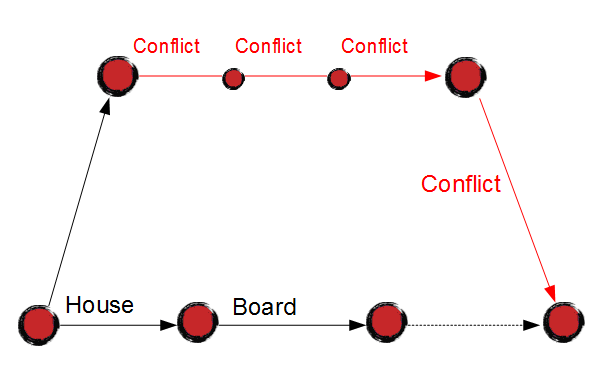
And although we have "House" unmerged, we still need to retest the release, because "Board" may impact the other features unexpectedly.
So, cherry-pick is a very bad practice and you should avoid using it if possible. To avoid it, please coordinate the delivery plan with your clients in advance and explain them how certain business decisions might impact the development costs and schedule.
Conclusion
I hope that this article will help:
- …the growing development teams to make their development process more efficient.
- …the project managers to plan team work and communicate to customers more successfully.
- …the product owners and investors to make better decisions.
Keep version control pattern in mind and use it to adjust development process to your project needs in the best way.
Please let me know if you have any questions.