To make it clear, first of all let's discuss the terms. Crowdsourcing – a word that is rather widespread among and known to a lot of people that has the meaning of distributing different tasks among a big group of people to collect opinions and solutions for specific problems. It is a great tool for business tasks? but how can we use it in ML?
To answer this question we create an ML-project working process scheme: first, we identify a problem as a task for ML; after that we start to gather the necessary data? then we create and train necessary models; and finally use the result in a software. We will discuss the use of crowdsourcing to work with the data.
Data in ML is a very important thing that always causes some problems. For some specific tasks we already have datasets for training (datasets of faces, datasets of cute kittens and dogs). These tasks are so popular that there is no need to do anything special with this data.
However, quite often there are projects from unexpected fields for which there are no ready-made datasets. Of course, you can find a couple of datasets with limited availability, which partly would be connected with the topic of your project, but they wouldn't meet the requirements of the tasks. In this case we need to gather the data by, for example, taking it directly from the customer. When we have the data we need to mark it from scratch or to elaborate the dataset we have which is a rather long and difficult process. And here comes crowdsourcing to help us to solve this problem.
There are a lot of platforms and services to solve your tasks by asking people to help you. There you can solve such tasks as gathering statistics and making creative things and 3D models. Here are some examples of such platforms:
- Yandex. Toloka
- CrowdSpring
- Amazon Mechanical Truck
- Cad Crowd
Some of the platforms have wider range of tasks, other are for more specific tasks. For our project we used Yandex. Toloka. This platform allows us to collect and mark data of different formats:
- Data for computer vision tasks;
- Data for word processing tasks;
- Audiodata;
- Off-line data.
First of all, let's discuss the platform from the computer vision point of view. Toloka has a lot of tools to collect data:
- Object recognition and field highlighting;
- Image comparison;
- Image classifications;
- Video classifications.
Moreover there is an opportunity to work with language:
- Work with audio (record and transcribe);
- Work with texts (analyze the pitch, moderate the content).
For example, we can upload comments and ask people to identify positive and negative ones.
Of course, in addition to the examples above Yandex.Toloka gives an ability to solve a big range of tasks:
- Data enrichment:
- questionnaires;
- object search by description;
- search for information about an object;
- search for information on websites.
- Field tasks:
- gathering offline data;
- monitoring prices and products;
- street objects control.
To do these tasks you can choose the criteria for contractors: gender, age, location, level of education, languages etc.
At first look it seems great, however, there is another side of it. Let's have a look at the tasks we tried to solve.
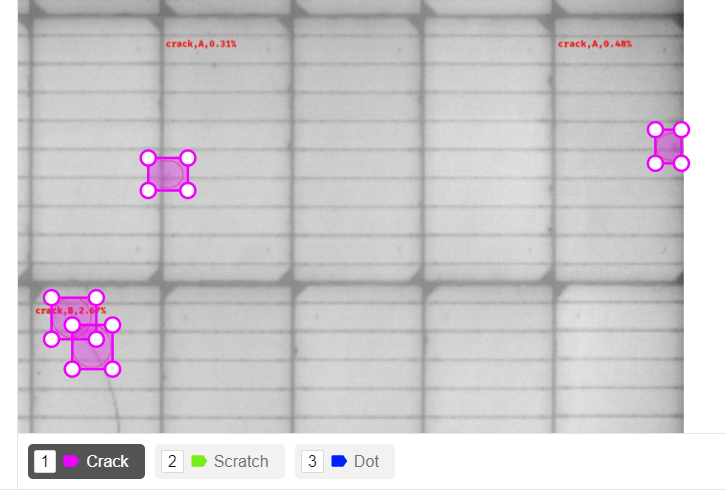
First, the task is rather simple and clear – identify defects on solar panels. (pic 1) There are 15 types of defects, for example, cracks, flare, broken items with some collapsing parts etc. From physical point of view panels can have different damages that we classified into 15 types.

The first problem was that shapes were different (pic 2) It could be circle, rectangle, square and the outline could be closed or could be not.




What could be done with low-quality marking? How could we make all circles and ovals into coordinates and markers of types? Firstly, we binarized (pic 6 and 7) images, found outlines on this mask and analyzed the result.

- Identify rectangle:
- mark all outlines – "extra" defects;
- combine outlines – large defects.
- Test on image:
- Text recognition;
- Compare text and object.
To solve these issues we needed more data. One of the variants was to ask the customer to do extra marking with the tool we could provide with. But we should have needed an extra person to do that and spent working time. This way could be really time-consuming, tiring and expensive. That is why we decided to involve more people.
First, we started to solve the problem with text on images. We used computer vision to recognise the text, but it took a long time. As a result we went to Yandex.Toloka to ask for help.
To give the task we needed: to highlight the existing marking by rectangle classify it according to the text above (pic 8). We gave these images with marking to our contractors and gave them the task to put all circles into rectangles.
- All objects in spite of the defect type were marked by first class;
- Images included some objects marked by accident;
- Drawing tool was used incorrectly.
We decided to put the contractor's rate higher and to shorten the number of previews. As a result we had better marking by excluding incompetent people.
Results:
- About 50% of images had satisfying quality of marking;
- For ~ 5$ we got 150 correctly marked images.
Second task was to make the marking smaller in size. This time we had this requirement: mark defects by rectangle inside the large marking very carefully. We did the following preparation of the data:
- Selected images with outlines bigger than it is required;
- Used fragments as input data for Toloka.
Results:
- The task was much easier;
- Quality of remarking was about 85%;
- The price for such task was too high. As a result we had less than 2 images per contractor;
- Expenses were about 6$ for 160 images.
We understood that we needed to set the price according to the task, especially if the task is simplified. Even if the price is not so high people will do the task eagerly.
Third task was the marking from scratch.
The task – identify defects in images of solar panels, mark and identify one of 15 classes.
Our plan was:
- To give contractors the ability to mark defects by rectangles of different classes (never do that!);
- Decompose the task.
In the interface (pic 9) users saw panels, classes and massive instruction containing the description of 15 classes that should be differentiated. We gave them 10 minutes to do the task. As a result we had a lot of negative feedback which said that the instruction was hard to understand and the time was not enough.

Results:
- The task was too complicated:
- a small number of contractors agreed to do the task;
- detection quality ~50%, classification – less than 30%;
- most of the defects were marked as first class;
- contractors complained about lack of time (10 minutes).
- The interface wasn't contractor-friendly – a lot of classes, long instruction.
Result: the task was stopped before it was completed. The best solution is to divide the task into two projects:
- Mark solar panel defects;
- Classify the marked defects.
Project №1 – Defect detection. Contractors had instructions with examples of defects and were given the task to mark them. So the interface was simplified as we had deleted the line with 15 classes. We gave contractors simple images of solar panels where they needed to mark defects by rectangles.
Result:
- Quality of result 100%;
- Price was 20$ for 400 images, but it was a big percent of the dataset.
As project №1 was finished the images were sent to classification.
Project №2 – Classification.
Short description:
- Contractors were given an instruction where the examples of defect types were given;
- Task – classify one specific defect.
We need to notice here that manual check of the result is inappropriate as it would take the same time as doing the task.So we needed to automate the process.
As a problem solver we chose dynamic overlapping and results aggregation. Several people were supposed to classify the same defects and the resultx was chosen according to the most popular answer.
However, the task was rather difficult as we had the following result:
- Classification quality was less than 50%;
- In some voting classes were different for one defect;
- 30% of images were used for further work. They were images where the voting match was more than 50%.
Trying to find the reason for our failure we changed options of the task: choosing higher or lower level of contractors, decreasing the number of contractors for overlapping; but the quality of the result was always approximately the same. We also had situations when every of 10 contractors voted for different variants. We should notice that these cases were difficult even for specialists.
Finally we cut off images with absolutely different votes (with difference more than 50%), and also those images which contractors marked as "no defects" or "not a defect". So we had 30% of the images.
Final results of the tasks:
- Remarking panels with text. Mark the old marking and make it new and accurate – 50% of images saved;
- Decreasing the marking – most of it was saved in the dataset;
- Detection from scratch – great result;
- Classification from scratch – unsatisfying result.
Conclusion – to classify areas correctly you shouldn't use crowdsourcing. It is better to use a person from a specific field.
If we talk about multi classification Yandex.Toloka give you an ability to have a turnkey marking (you just choose the task, pay for it and explain what exactly you need). you don't need to spend time for making interface or instructions. However, this service doesn't work for our task because it has a limitation of 10 classes maximum.
Solution – decompose the task again. We can analyze defects and have groups of 5 classes for each task. It should make the task easier for contractors and for us. Of course, it costs more, but not so much to reject this variant.
What can be said as a conclusion:
- Despite contradictory results, our work quality became much higher, defects search became better;
- Full match of expectations and reality in some parts;
- Satisfying results in some tasks;
- Keep it in mind – easier the task, higher the quality of execution of it.
Impression of crowdsourcing:
| Pros | Cons | |---|---| | Increase dataset | Too flexible | | Increasing marking quality | Low quality | | Fast | Needs adaptation for difficult tasks | | Quite cheap | Project optimisation expenses | | Flexible adjustment | |